Keytap: description and some random thoughts
Introduction
The following post will provide some technical details about the keytap tool. I would also like to share some of my thoughts regarding the project. Source code is available here.
Description
The main goal is to exploit the sound produced by pressing keyboard keys as a side channel in order to guess the content of the text being typed. To achieve this, the algorithm takes as input a training set, consisting of an audio recording, together with the corresponding keys being typed during this recording. Using this data, the algorithm learns what is the sound of different keystrokes and later attempts to recognise the sounds only using captured audio. The training set is very specific, in a sense that it targets a single setup - keyboard, microphone and relative position between the two. Changing any of these factors renders the approach useless. As a bonus, the current implementation does the prediction in real-time.
The main steps involved in the implementation are the following:
- collecting training data
- creating a prediction model (learning step)
- keypress detection
- predicting the key for a detected keypress
Collecting training data
In the current implementation, the sound in-between keystrokes is simply discarded. We keep only the audio within 75-100 ms before and after the actual press. This is a bit tricky, as it seems there are random delays between the key being pressed and the event being captured by the program - most likely both hardware and software factors are involved.
For example, here is what the full audio waveform of pressing the letter ‘g’ on my keyboard looks like:
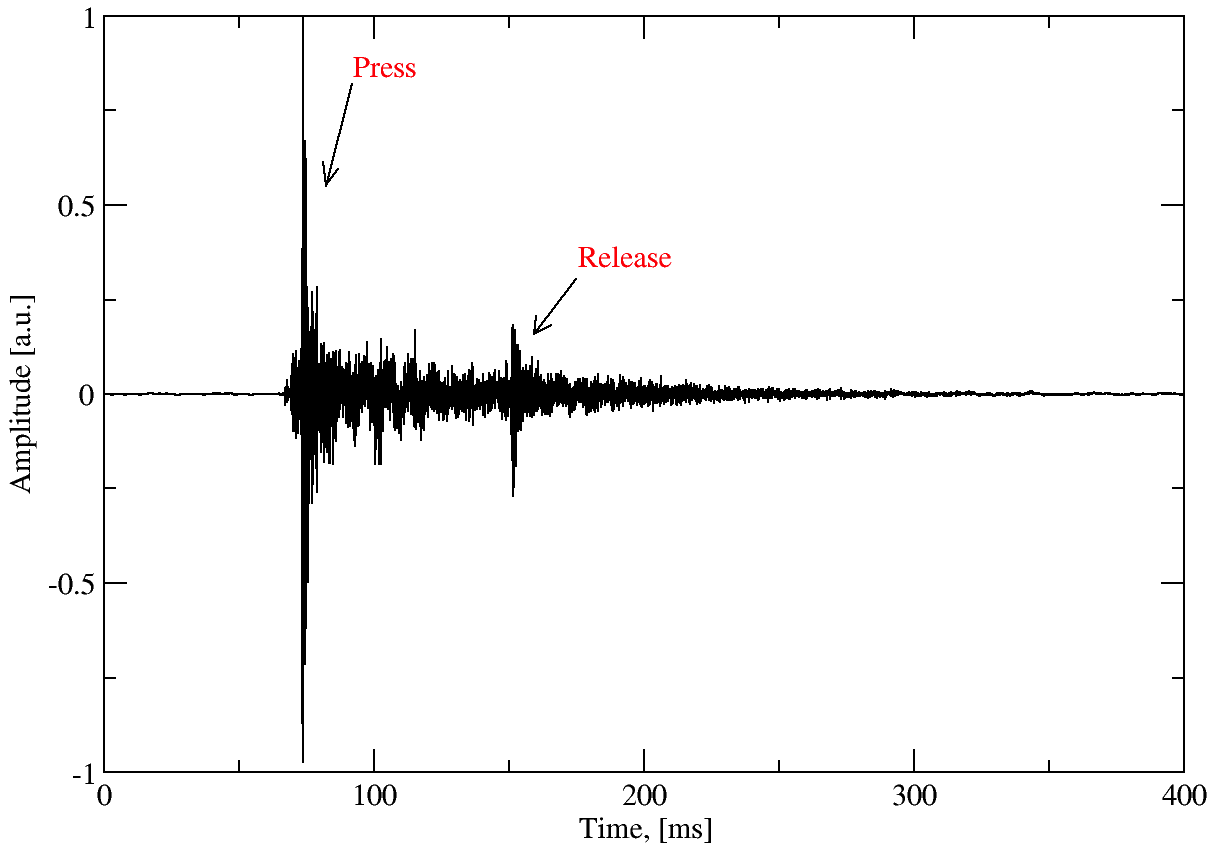
As can be seen from the figure, there is an additional release peak shortly after the press peak. Keytap simply ignores the release peaks. It might be possible to extract additional information here, but for the sake of simplicity the data is discarded. In the end, the training data for this key looks like this:
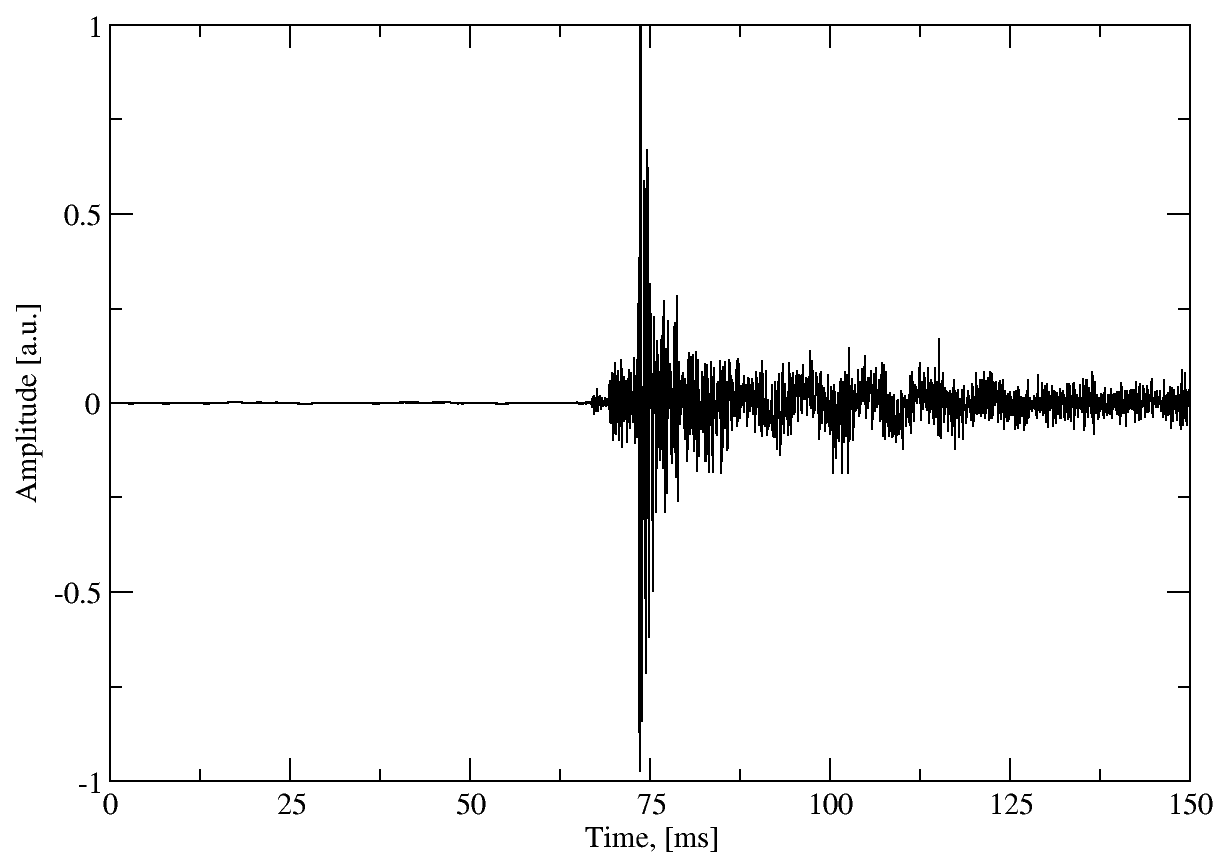
Obviously the 75 ms window imposes a certain limitation on the typing speed - if keystrokes overlap within this time period, then the training data for different keys gets intermixed.
Another observation is that the more training waveforms for a certain key are available - the better. Combining multiple waveforms helps mitigate ambient noise. Additionally, individual presses might sound slightly different, depending on the way the user presses the key, so one could potentially capture the various ways a keystroke might sound.
Creating a prediction model
Here is where people can get very creative - machine learning, artificial intelligence, neural networks, etc. Keytap uses a very simplistic approach. For each training key we perform 3 steps:
- Align the peaks of the collected waveforms. This helps avoid random time delays before the detection of the key press event (explained earlier).
- Finer alignment of the waveforms based on a similarity metric. Sometimes, the peak is not the best indicator, so we use a more precise approach.
- Simple weighted averaging of the aligned waveforms. The weights are defined by the similarity metric.
We don’t want to apply step 2 directly because the calculation of the similarity metric can be CPU intensive. So step 1 effectively narrows down the alignment window and reduces the amount of computation.
After step 3, we end up with a single averaged waveform for each key. This is later compared to the real-time captured data and used to predict the most probable key.
The similarity metric used in keytap is Cross Correlation (CC):
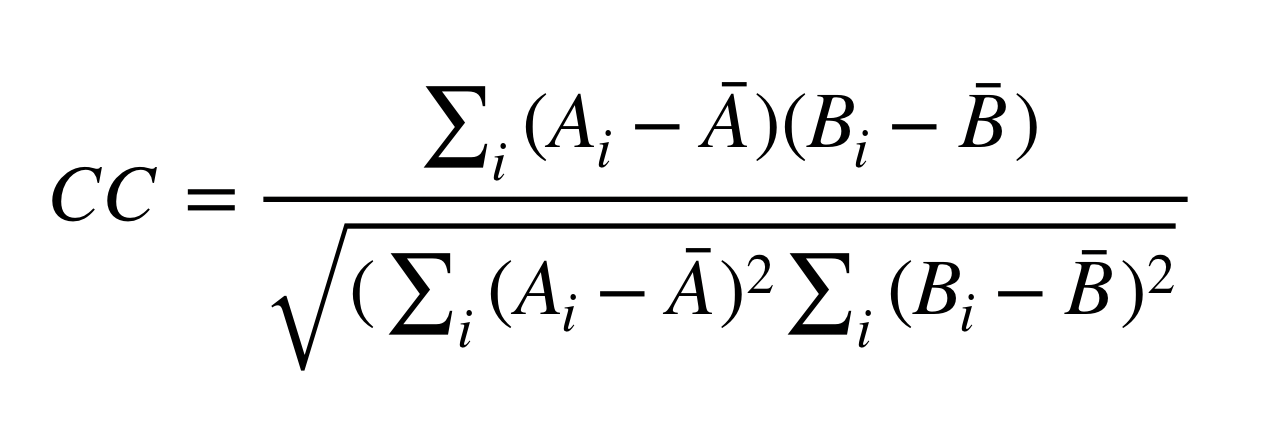
Here Ai and Bi are the waveform samples of the two waveforms being compared. Higher CC values correspond to more similar waveforms. Other similarity metrics can be used too.
Timing information of the intervals between keypresses can potentially be integrated in the prediction model. I have avoided such aproaches so far as they are more difficult to implement.
Keypress detection
Keytap uses a relatively simple thresholding technique to detect keypress events in raw audio. Obviously, we expect a huge peak when the user presses a key, so this is what we are looking for. The threshold is adaptive - it is relative to the average sample intensity for the past several hundred milliseconds.
The approach is definitely not perfect and I wish I knew how to make a more robust approach for detecting the press events. I also don’t like the free parameter associated with the current thresholding techinique.
Predicting the key for a detected keypress
Once a potential keypress event is identified, we locate the position of the peak in the waveform and calculate the similarity metric of that portion of the waveform against all averaged waveforms in the training data. We allow for a small alignment window around the peak (as described earlier). We expect that the highest similarity metric will correspond to the key being typed.
Some observations
I noticed that when the algorithm fails to detect the correct key, it still predicts a nearby key. Nearby in the sense that it is located next to the true key. There are 2 explanations that I can think of for this:
- Nearby keys on the keyboard emmit similar sounds
- The position of the key relative to the microphone is very defining for the prediction in this approach
I think option 1 is not very likely though.
Another observation is that mechanical keyboards are much more vulnerable to this type of attack compared to non-mechanical ones.
Keytap2
I am pretty sure it is possible to implement a prediction approach that does not require to collect training data at all. Given that the user types a text in a certain known language (e.g. English), the statistical information about N-grams in that language, combined with the similarity metric of the detected keypresses could be enough to detect the text being typed. Effectively, it boils down to breaking a substitution cypher.
Keytap2 is an attempt to demonstrate such type of an attack. I am still working on it - I am stuck on the part of clustering the keypress based on their CC. But I think at least I have the substitution cypher breaking part ready. Will try to provide more details when it actually works.
[Updated: 4 Dec 2018] For anyone interested in this problem, I posted the Keytap Challenge.
Final words
There are some publications available on this topic in the scientific literature. One particular approach I was partially inspired by is the Don’t Skype & Type! [1]. But mostly, I approached the problem without looking too much into details about what other people have already done - this way it’s more fun.
I am honestly, very surprised about the huge attention this got - didn’t exepect it all. It all started from a random Hacker News comment that I posted and it being noticed by a famous developer. And then Twitter flooded my repository :).
Anyway, I hope this is useful to someone. Cheers!
[1] Don’t Skype & Type! Acoustic Eavesdropping in Voice-Over-IP, Alberto Compagno, Mauro Conti, Daniele Lain, Gene Tsudik